
秒杀项目整理
一、基础秒杀项目概述
1. 项目架构

接入层模型(View Object):与前端页面对接的模型,用于前端页面的展示,是一个聚合模型。
业务层(Domain Object):领域模型,是业务的核心模型,拥有完整的生命周期,是贫血模型。和业务相关,因此是最先设计的。
数据层(Data Object):数据模型,同数据库映射,用以ORM方式操作数据库的模型。
贫血模型:对应的Domain Model只包含基础的属性、get、set方法,不包含具体的业务逻辑。而业务逻辑则放在调用贫血模型的service中。
这种设计模式其实是和面向对象的思想背道而驰的,它是一种面向过程的思想。它破坏的面向对象的封装性。面向对象主张将数据和行为绑定在一起,对外提供接口。
这里项目中采用贫血模型可能因为只有秒杀业务逻辑,相对简单,开发迅速。对于复杂的业务逻辑,则需要更完善的设计,并采用充血模型。
2. 对象、模型关系

图中的三层对应了上述的三种模型。并且可以看到模型间进行了各种组合/聚合。
(1) 商品模型ItemModel组合了数据库中的商品数据表ItemDO和库存数据表ItemStockDO,并且如果该商品在某个秒杀活动中,他就会和秒杀活动模型PromoModel聚合成秒杀商品模型,最后将这两个聚合成的模型组合成ItemVO给前端展示。
(2) 用户模型UserModel包含了用户数据表和用户密码表。这里将用户数据和用户密码进行分表设计,因为用户密码可能存放于加密机或者其他数据库中,其次除了登录、注册等操作之外,其他用户相关的操作都用不到密码,因此在接口调用UserModel的时候,可以减少一次数据库的查询,并且可以节省表空间。
补充用户基本信息和密码分表设计的原因:
- 性能方面:登录时只需要用户Id和密码,增加查询的效率。复杂的登录系统可能还有登录IP地址、上次登录时间、登录设备等,也可能有各种第三方登录的授权信息,如果和用户基础信息放一个表,会显得非常臃肿,后期添加新的登录方式也很难维护
- 安全方面:防止查询用户信息的时候,查到用户密码;防止SQL注入。
(3) 我们对商品数据和库存数据也进行了分表,因为库存的操作是非常耗时耗性能的,库存交易时,会对库存加行锁进行减库存。我们将库存表分出去后,如果后期对商品的库存进行优化时,更加方便。比如对同一个商品的itemId号模10,分到10个不同的数据库中,以减少单个数据库性能的消耗,提高并发性。
库存表的优化也可以根据库存量除以10,分到10条记录中,这样也可以减少数据库性能消耗,相当于负载均衡到10条记录上。
3. 类图
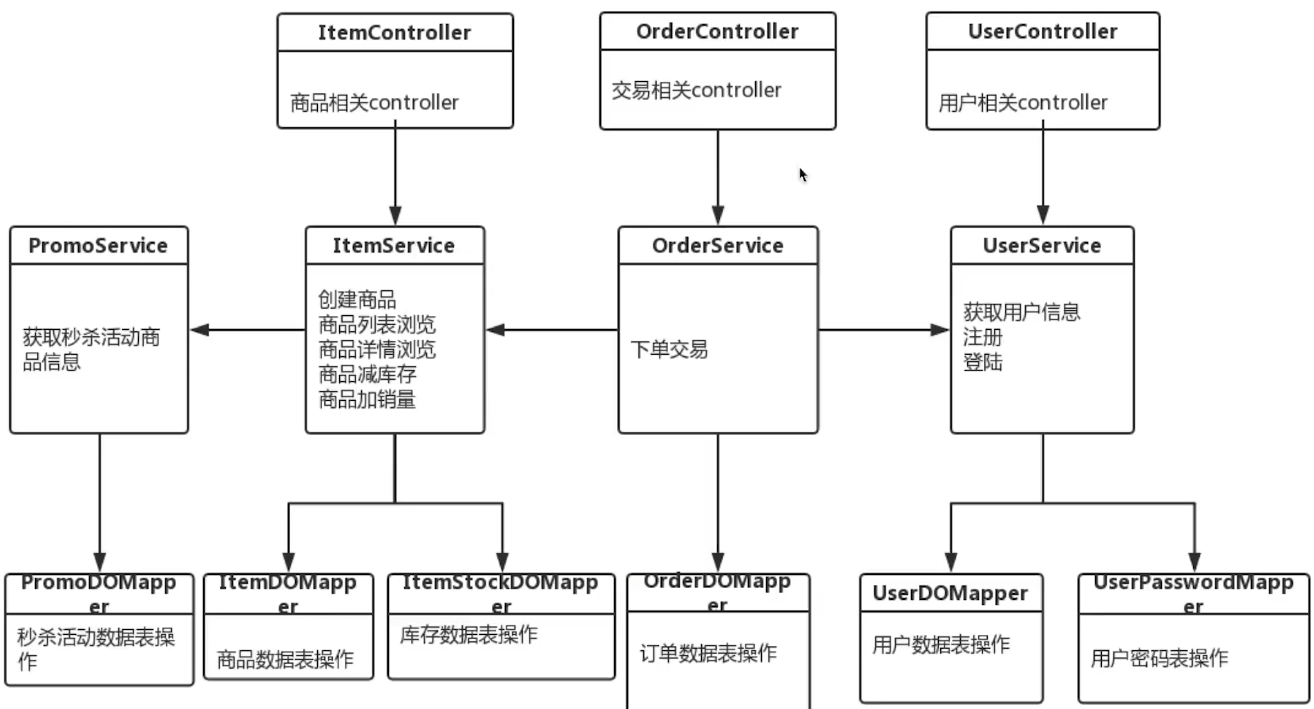
二、各模块流程
三、分布式部署
nginx反向代理,负载均衡;分布式会话管理;使用redis实现分布式会话管理;
3.1 Java应用程序
部署相对简单,在对应服务器安装jdk,在服务器上编写application.properties配置文件,该配置文件会覆盖SpringBoot内的配置,因此可以根据不同的服务器配置不同的属性。最后通过deploy.sh脚本启动应用服务器。
deploy.sh脚本实例如下:
1 | nohup java -Xms400m -Xmx400m -XX:NewSize=200m -jar miaosha.jar --spring.config.addition-location=/var/www/miaosha/application.properties |
3.2 MySQL部署
安装相关依赖,需要注意的点是数据库远程开放端口连接,简单说就是开放ip白名单,只有你的应用服务器ip能访问数据库,以保证安全性。
3.3 nginx部署
nginx可以作为web服务器、动静分离服务器、反向代理服务器等。

- 动静分离:在实现反向代理的时候,如果是静态资源,就直接在nginx的静态资源路径去读取,无需访问后端服务器;
项目里采用的是nginx的openResty框架。
OpenResty是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
OpenResty通过汇聚各种设计精良的 Nginx 模块(主要由 OpenResty 团队自主开发),从而将 Nginx 有效地变成一个强大的通用 Web 应用平台。这样,Web 开发人员和系统工程师可以使用 Lua 脚本语言调动 Nginx 支持的各种 C 以及 Lua 模块,快速构造出足以胜任 10K 乃至 1000K 以上单机并发连接的高性能 Web 应用系统。
OpenResty® 的目标是让你的Web服务直接跑在 Nginx 服务内部,充分利用 Nginx 的非阻塞 I/O 模型,不仅仅对 HTTP 客户端请求,甚至于对远程后端诸如 MySQL、PostgreSQL、Memcached 以及 Redis 等都进行一致的高性能响应。
3.3.2 master-worker模型

nginx的进程模型由一个master进程和多个相互独立的worker进程组成,并且这些worker进程都是单线程的。
启动nginx服务器后,nginx首先会创建一个master进程,然后会根据配置的worker process的数量来启动相应数量的工作进程。这里的master进程和worker进程式父子进程的关系,即worker进程是由master进程fork出来的。由于这种关系,master进程就可以管理所有worker进程的内存空间。
master进程用于管理worker进程,而worker进程才是用于处理客户端连接的。在启动nginx后,master会创建一个socket的文件句柄,用于listen在nginx的外部服务端口上面。这时master进程就会采用epoll的多路复用模型。当客户端访问外部服务端口,会发送http请求,然后进行tcp三次握手,会向端口发起socket的connect操作,这时epoll模型会产生对应的回调方法,nginx的master进程是不会处理这个accept操作的,而是由worker进程去处理。
那由哪个worker进程去处理呢?nginx在内存中有一个accept mutex,类似于互斥锁,那么worker进程会去争抢这个互斥锁,抢到锁的那个worker进程就去处理这个连接,并且以后对应这个connect的socket的cend和receive都由这个worker进程去负责。
这也是nginx高效的原因之一。
3.3.3 nginx平滑重启的原理
master进程发送信号给worker进程,worker进程将所有的socket句柄交给master管理,然后master会读取配置文件,创建一个新的worker进程,再将之前的socket句柄交给新的worker进程管理。
3.4 分布式会话(重点)
3.4.1 为什么要分布式会话?
单体的实现无法应用于分布式场景。比如:用户在服务器A进行登录,下一次的路由请求又被分到服务器B上,那么他对应的sessionId就不存在了。
3.4.2 解决方案
-
nginx的负载均衡策略为ip_hash
同一个ip会被分到同一个目标服务器上,问题是如果目标服务器宕机或重启,session就会丢失。
-
将session集中存储到redis中(常用策略)
3.4.3 实现
这里简单描述一下实现。导包安装啥的不说了。需要注意的是redis的序列化方式,默认是JDK的序列化方式,直接用会报错。一种方案是我们的模型需要实现Serializable接口;另一种是修改redis的序列化方式,改为JSON或者String。
我们可以使用UUID作为token,记住设置key的过期时间,例如:
1 | String uuidToken = UUID.randomUUID().toString(); |